Beyond Flatland: Machine learning and the end of the two-party binary
Crippled by faction, we as democratic populations should honor that tradition, and keep designing.
 Colin Megill
Colin Megill
- This article was originally published JUNE 24, 2019 in Civicist. It is republished here under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
In democracies worldwide, billions of citizens hold an untold number of interests, opinions and positions. Political reality on the ground is vastly more complex than our political symbols and categories allow us to express. Our political choices are artificially constrained by existing abstractions that either compress us into just two large opposing parties, or in the case of proportional representation systems, a mix of smaller parties. Either way, the real complexity of people’s opinions is squashed. There are thousands of overlapping interest groups, not just two tribes. There are hundreds of thousands of issues and sub issues, not the small handful the media focus on during election cycles.
Elections and referendums severely constrain the information populations are able to send to governing bodies. Our current methods of compressing the will of the masses into party platforms, for example, leave out the 42% of Americans who now identify as independents, and whose voices are excluded from the policy formation process at every step.
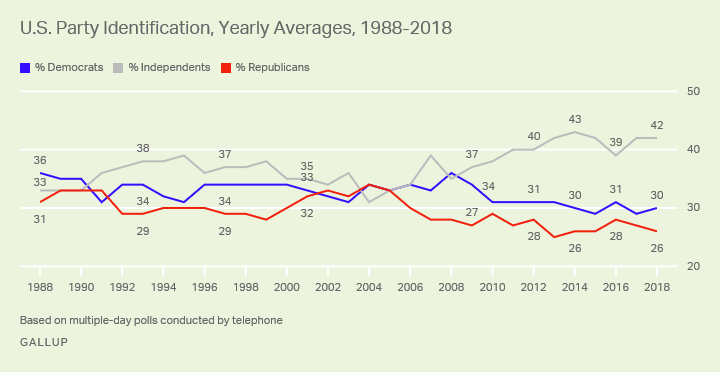
The numbers are about the same in the United Kingdom. This is especially true after Brexit. According to the Independent “Millions of voters feel politically homeless and would consider backing a new centre-ground party … almost half of those questioned … said both that they did not feel represented by any established party and that a new organisation would have a chance of winning their vote.”

As a democratic population, what we ‘see’ is heavily influenced by what our representations allow us to see. Political parties are like a very low resolution photograph, obscuring critical aspects of what voters might actually want or what they would be willing to accept. Making things worse, party platforms cast off consensus issues in favor of wedge issues useful for gaining power. The Brexit referendum, alternatively, wrapped up thousands of issues into a binary vote and created a new lens — “Leave” or “Remain” — through which to see the polity. The scourge of polarization and deadlock in modern politics is a function of our mechanisms for simplifying citizen input like these, not a feature of our constitutions, governmental structures, or our populations. We live in a political flatland because our categories and our tools for thinking about ourselves and others are one dimensional.
What might it offer us to make meaning of our political spaces — of ourselves as a body of citizens — as a whole, in more dimensions and in higher resolution? To answer this question, we’ll need to look to alternative methods of citizen participation, ways that move past resolving every issue by relying on a handful of critical votes like the vote for President or referendums like Brexit.
The Office of Presidential Correspondence under President Obama’s Administration gave us a glimpse of a data source and process. During Obama’s tenure, the White House received roughly 10,000 letters per day from ordinary people. They were read by a rotating group of 300 volunteers and a handful of dedicated staff, who selected 10 letters for the President to read each day. The 10 letters were chosen as the best compromise — broadly representative of the population’s thoughts and feelings while accepting that he couldn’t possibly read and digest the full spectrum of what was pouring in. They were the result of a kind of compression algorithm run by a particularly empathic, qualitatively oriented human computer, fed a raw input of the population’s agenda in its own words. This was a process deeply rooted in respect for the human voice.
This practice is not common, however. Recently, I spoke with an individual on the staff of one of the major departments in the US federal bureaucracy. The department was facing a public comment period in which they were expecting nearly one million comments. There was a single Federal employee tasked with reviewing the million plain-text comments. The same policy process would also see input from focused industry lobbyists.
While we now live in an age of mass participation, where everyone has a multitude of ways of expressing their voice, our formal government structures haven’t caught up. Today’s democracies are still shortchanging their opportunities to enhance issue-based democratic policy making. As a result, there is enormous pressure to discuss every issue during an election season — a process that predictably leaves citizens feeling unsatisfied and the government without a discernible mandate. We need a scalable compression mechanism for making better meaning of the rich, qualitative data citizens can provide. Could we automate, scale and improve on the process that happened in Obama’s letter room?
While the problems of democratic governance need special consideration, processing this scale of input is not a new problem to industry. Netflix, for instance, drives production decisions by using automated data collection and analysis: the company looks at the behavior of its expansive TV- and movie-watching population and use that data to suggest other shows to viewers, as well as to inform decisions about what new shows to produce. The results of their analysis have overturned conventional thinking about who would want what, as Janko Roettgers wrote in Variety in 2017:
Netflix used to recommend content based on the region that its users were in, following the general school of thinking that subscribers in South America probably would prefer different fare than subscribers in Canada. But upon looking closer at the data, the company realized that this wasn’t actually true,” Netflix VP of Product Todd Yellin said. “We find that to be greater and greater nonsense, and we are disproving it every day.”Instead, Netflix is now dividing up its subscriber base into 1,300 taste communities, which are solely based on past viewing behavior. Each and every user can belong to multiple such communities, and all of these communities spread across the globe. Sure, Yellin admitted, German comedians may be more popular in Germany, but there’s also plenty of users in the U.S. who turn into their shows. “A big part of personalization is finding taste communities globally,” Yellin said.
The result of this data analysis are categories far more niche than the one dimensional flatland of ‘Comedy’ and ‘Drama.’ In fact, Netflix breaks movies into 76,000 categories like “Scary Cult Movies from the 1980s,” “Brain Food Docs,” and “Fight-the-System TV Shows.” Movies can belong to multiple categories, just like viewers can belong to multiple taste communities. For Netflix, the goals are clear: better recommendations and more views mean higher customer engagement, and thus retention. The more valuable the platform is, the more likely people are to recommend it and new customers are to join.
Machine learning, along with a substantial profit motive, has rendered the most accurate portrait of the global movie and TV watching public ever created.
Now that Netflix (and the rest of us) can look more accurately at the signals created by large populations, we’re all seeing more details, and finer grain categories that describe us. Netflix can ‘see’ a lot more of the preferences of their community, because they have rendered a more detailed portrait of the complex preference space than Blockbuster ever did. If Netflix presupposed there were only a handful of categories — comedy, drama, horror, war, sports — that would define the resolution it would see its users. It would also influence the resolution at which its users would see themselves, and the language they would have to describe themselves. Imagine if we had the same fine-grained, real-time awareness of the complexity of public opinion across all issues, even issues the government isn’t aware of or ready to consider yet.
There are better ways to represent citizens using machine learning, and these representations can be meaningful in the policy process and lead to better policy outcomes. Driven by the communication challenges inherent in protest movements like Occupy and the Arab Spring, this problem led our software team to create the open source data science platform Polis.
Polis offers a rough ethnography of a population, showing areas of consensus and disagreement across an immense spectrum of possibilities. The math inside it is roughly the same as the recommender engines Spotify or Netflix are using – it’s looking for similarities and differences among people, as well as global consensus.
In the fall of 2016, I was in Turin, Italy, speaking at the Scuola di Tecnologie Civiche (School of Civic Tech) conference. Italy was focused at the time on the upcoming constitutional referendum, which was to decide the fate of the powers of the Italian executive branch, as well as Renzi’s presidency. Announcing the referendum, Renzi threatened to resign if he lost his bid to centralize powers (he lost, and did resign).
At the behest of the organizers, I ran a mock deliberation on the referendum in an intimate setting of forty attendees. Opinions regarding the referendum were submitted by participants, who agreed and disagreed on statements submitted by other attendees. As participants took positions on the statements submitted by their peers, Polis’ machine learning algorithms ran automatically on the resulting opinion matrix. Think: a spreadsheet where the columns are statements instead of movies, and the rows are voters rather than movie watchers, and each cell is an agree or disagree rather than a rating. The algorithms surfaced patterns of opinion amongst participants across all statements, and formed clusters.
Some obvious opinion clusters emerged – those in favor of Renzi and centralization and those opposed. But a simple, piercing statement by one participant garnered unanimous support: “Referendums shouldn’t be used as an election surrogate.” Regardless of where they stood or their level of expertise, participants agreed that Renzi had invalidated the referendum by threatening to resign if his side lost – thus ensuring the opposition of political rivals regardless of their stance on the constitution. Meanwhile, across other statements, it was clear that a number of Renzi opponents were open to changing the constitution. What was an absolutely polarized issue when viewed through the lens of a binary vote on a referendum, was in fact a public with complex and nuanced views, willing to consider various propositions and tradeoffs, and eager to challenge the processes by which they were being represented. Running engagements around the world, we’ve seen that same pattern play out again and again.
As of mid 2019, Polis has been used by multiple national governments, in one high profile case, it served as an input to facilitate rulemaking in the process of regulating Uber in Taiwan. It’s proven able to overcome long standing deadlocks on complex issues with highly polarized stakeholders by visualizing common ground, as in Taiwan’s debate on online alcohol sales. Canada’s federal government has now run multiple engagements, one of which involved the future of Canada’s visual arts marketplace.
Polis was recently run in Germany with over 30,000 people, who produced nearly two million votes on hundreds of crowd submitted statements. Columbia University ran a pilot in Bowling Green, Kentucky, with thousands of Americans participating (roughly 2% of the population of the city) who live in a purple district. This was written up as a report as well as in Slate, and covered by Civicist. New Zealand’s Department of Conservation is running public engagements with partners in independent media, and Singapore’s Ministry of Culture is talking to thousands of youth at a time. New York City’s Department of Homeless Services is running conversations related to homelessness with frontline staff, who are all able to testify to their experiences in their own words, which can be validated by their colleagues and peers.
There is no barrier to scaling the method up to the entire voting-age population of a democracy by strategically sampling, say, 10,000-20,000 people at a time, or even creating ‘always on’ citizen assemblies of that scale or much larger. The challenge now is integrating new computational methodologies with stubborn, legacy policy making processes. We also have a collective choice, whether these models of the public are to be defined by open data and reproducible, open methods, or proprietary and unable to be audited.
Not every decision in a representative democracy will involve the public. But when the government does go to the public, seeking legitimacy and wisdom about the population’s lived experiences and preferences, democratic institutions can do better. The government can engage the public on issues and sub issues. It can engage people in rich and dynamic ways that let them know their voices are heard. It can engage the population early — when there are more problems to solve than pages of legalese written — and involve them in agenda setting.
New capabilities for reconciling complexity at scale in democratic populations mean new assumptions regarding the representation of populations. Future democratic systems must be much more effective at managing and integrating qualitative signals from the population at scale to avoid polarized deadlock. Systems of representative government were intentionally designed to break the back of faction. Crippled by faction, we as democratic populations should honor that tradition, and keep designing.
 (This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.)
(This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.)